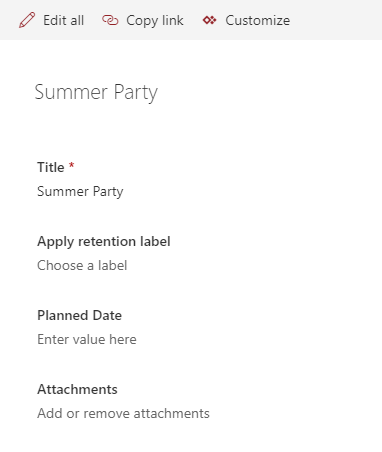
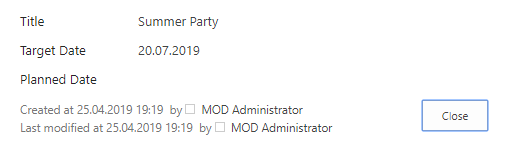
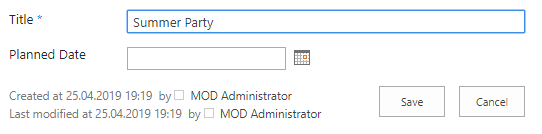
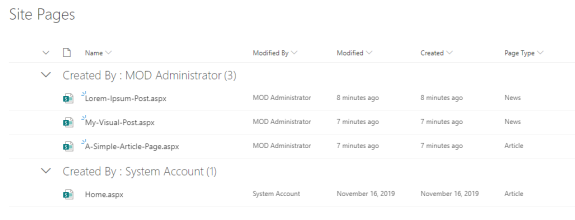
In SharePoint Online modern pages, the article pages and the news pages are stored together in the Pages library. Using the available columns in the view we have no options to make visible, what type a page has.
To resolve this issue, create a new calculated column in the Pages library with the following formula:
=IF([Promoted State]=0,”Article”,”News”)
This formula uses the hidden field “Promoted State” that could be used to differentiate between the two page types:
0 for an article page
1 for an unpublished news page
2 for a published news page
The result will look like this, when you have your created column in a view:
In the Site Pages library in the modern interface in SharePoint Online we can have article pages and news pages. This page type is set, when the page is created by the author. But how can this be changed, after the page is created?
The content type of a page has a hidden column named “PromotedState”. The value can be
0 for an article page
1 for an unpublished news page
2 for a published news page
To modify the site type, some simple PowerShell scripting is helpful. Connect to the SharePoint site with Connect-PnPOnline and then…
… when we have an article page and want to move it to a news page, this script can be used:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
… or when we have a news page and want to change it to an article page, the following script could be used:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
For images in the user interface in SharePoint, Microsoft makes use of the formatmap32x32.png and formatmap16x16.png that are stored directly on the server and could be reached via the link “/_layouts/15/1033/images”.
How can we use these images, when we want to provide out own user interface?
Let’s assume, we want to use the workflow symbol , how can we address this image in the map?
The symbol is found in row 15 and column 5 in the map. To make it visible using html and css, we can use this simple snippet:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The classes used in the span are important. We see the image addressed in the img tag, but how do we get the values in the style attribute for top and left?
We can use the following formulas to get these values:
top = (((row – 1) * 34) + 1) * (-1)
left = (((column – 1) * 34) + 1) * (-1)
For our workflow symbol we will get for top the value -477 and for left the value -137. Add these values for the style attribute in the img tag and the symbol will be shown.
I would recommend not to use the formatmap16x16.png, because the rows and columns in this file are not that structured, as in the formatmap32x32.png. We do not have a simple formula to address a symbol in this file.
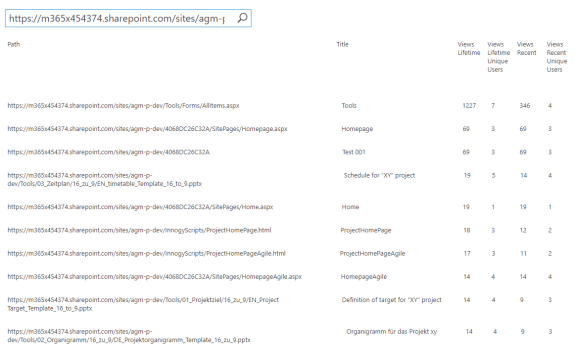
The following GitHub repositiory will show a simple solution to use SharePoint Search as the source for an overview of visits to a SharePoint site. The readme in the repository describes, how to recreate the solution without development. An example output could look like this.
Today I had to investigate a problem, where the type for a field in a SharePoint list changed from User to Lookup. Using the web interface for SharePoint it is not possible to do this modification.
A user field is internally a lookup field to the UserInformation list in the site collection, this could be proofed in the SchemaXml of the field. That means, this change did not modify or destroy any data. But we still do not know what happened to our list.
We where able to solve the problem by modifying the FieldTypeKind using PowerShell PnP. This member of the Microsoft.SharePoint.Client.Field class stores a value from the enum FieldType.
So, to solve this problem, we just needed 4 lines of code:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
In our case, running these commands could solve the problem. But be careful changing the FieldType, because I assume it could destroy the data in this field.
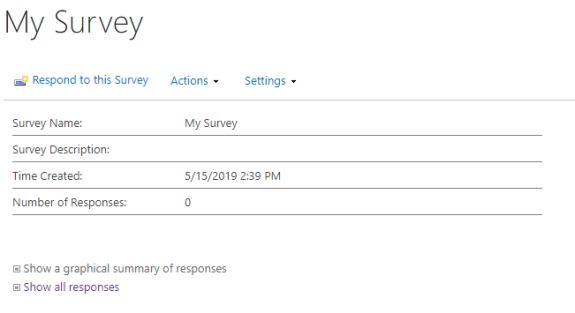
When we create a survey in SharePoint, an overview will be created with several information.
Under some circumstances it might be necessary, to hide the line with the Number of Responses. Because this is a simple html-table that shows the information, a Script Editor webpart and some jQuery could be used to solve this problem.
First, we need jQuery in our site. To make jQuery available, we can use PowerShell PnP, connect to our site and execute the following cmdlet:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Next, we open the overview page of the survey and switch into edit mode for the page (click the gear icon top right and select Edit Page). When in edit mode, insert a Script Editor webpart on the page (we find it in the category Media and Content). When the webpart is added, click Edit Snippet in the webpart and enter the following snippet:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
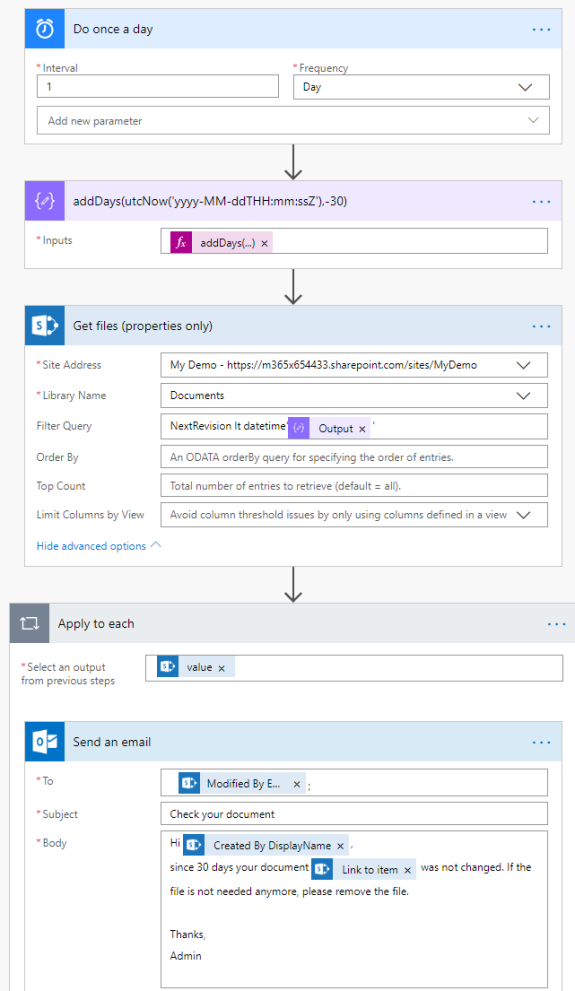
For a document library in SharePoint Online, I want to send notification mails for documents, where the “NextRevision” date is 30 days in the past or older. The Flow should run once a day.
This sample would send the mails each day, when a document was not modified. To avoid this behavior, add a field to the library, to mark that a notification was sent.
In some cases, it could be necessary to hide a field in the editform in SharePoint. This could easily be done with the SetShowInEditForm() method from the Client-side Object Model of SharePoint.
In this short demo, I have prepared a demo list with the fields “Target Date” and “Planned Date”. When a new item is created by a user, both fields could be edited. But, when the item was saved, we do not want to be able to modify the value in the “Target Date”.
In the web interface in SharePoint, we do not have any option to change the necessary property of the field. But with PowerShell, this problem could easily be solved. After we have established a connection to our SharePoint site, we can use these four lines of script to do the modification:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
When we are using a SharePoint site with modern UI, the field will always be removed, except when we add a new item, because the information pane is always opened in edit mode (in modern UI we do not have a separate view mode).
But when we switch back to the classic UI, we can see a difference.
Display form:
Edit form:
Just done, with a few lines in PowerShell.
Just, to have it complete: the Client-side Object Model has two other methods in the Field-class, SetShowInNewForm() and SetShowInDisplayForm(), to make a similar functionality available in the other forms for the list.
Yes, it is also possible to archive the same goal by modifying the edit form with PowerApps, when we use the modern UI. But this only works with the modern UI and there is still a need for using the classic UI, because we have other options in the classic interface actually not available in the modern UI.
The last days I was asked, how to handle indexing of pdf-files that contain scanned content. In these files the content often are just images and an OCR approach is needed to make the content readable and accessible for the crawler.
From my point of view, we have two options to answer the question. The first is a Flow, where we can use the ElasticOCR connector. Actually, the connector is in preview, but it can already get a trial license for your tests. The way of working of the connector creates a new version of the document with readable content for the crawler. Good approach and it does what I expected.
But there should already be another approach to answer the question. For environments that run on-premises, we are not able to use Microsoft Flow, and on the other hand, using this Flow connector will first copy the file and the content to another location, do the processing and then move the results back to our SharePoint or OneDrive library.
There are some development packages for OCR available, I tested with IronOcr. My approach is very simple: in the library, where the document is stored, I create a hidden text field, where I store the text content of the file after the OCR process is done. The SharePoint crawler will pick-up the content of the field and store all necessary information in the index for the search. Searching for any information from the document will show the document in the search results.
The following code is just the result of this proof-of-concept, nothing more. The first part is just the field definition, where the text content will be stored after ORC.
The second part is a very, very simple command line program that takes the item id of a document as the parameter, does the OCR for the document and stores the readable text in the text field of the file item.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
So, for handling these documents in the real world, we can use a remote event receiver for SharePoint (Online) or just a simple remote timer job. As always it depends on the environment, where we are working in.
I got the request to create a nice FAQ in SharePoint Online. The user interface should not be a simple list but should be fancy or modern. Additionally, the content should be in two languages, English and German.
So, what would be a simple approach for the solution? The content itself would be a custom list in SharePoint Online, where we have a choice field for the languages. For the answers we use a Note field with FullHtml style.
To display the contents of the list, we use some html, CSS and JavaScript in a Content Editor Webpart. In the JavaScript we query the list by language and build up some html that is added using jQuery. Finally, the added html gets a click function injected to show or hide the answer.
The html and JavaScript will look like this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
To create the structure for our solution, we are using just some PowerShell (with the SharePoint PnP extensions):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters

 , how can we address this image in the map?
, how can we address this image in the map?